



Comfy UI でひとまず画像が生成できる環境は前回の「準備編」で用意できました。
今回は Comfy UI をインストールした直後に何も考えずに生成した画像を出発点に、Stable Diffusion WebUI Forge で生成した画像のクオリティを目標に画質を向上させ、最終的にはフル HD サイズにするまでのワークフローを作っていきたいと思います。


その前に…
Comfy UI の基本操作については「雑に学ぶ ComfyUI」で「ComfyUI の基本操作」を御覧下さい。当方もこれで習得しました。と言うことで、基本的な操作方法については端折ります w
さらに準備編でインストールした ComfyUI-Manager を使って、画質向上および生成画像の拡大に使用する以下の拡張ノードを「 Costom Nodes Manager 」をクリックしてインストールしておいてください。
- ComfyUI Impact Pack
- ComfyUI Impact Subpack
- UltimateSDUpscale
ComfyUI Impact Pack は「Face Detailer」ノードなどの追加のために、UltimateSDUpscale は生成した画像をフル HD サイズに拡大するためのノードを追加するために使います。
プロンプトを変更
後述しますが、 Comfy UI では LoRA はノードで追加します。従って、プロンプトに LoRA を適用するための記載をする必要はありません。これらの記載は削除してください。
また EasyNegative や negative_hand などの Embedding は、Stable Diffusion WebUI では、ネガティブプロンプトに単に「EasyNegativeV2」と書いていたものを「embedding:EasyNegativeV2」と修正する必要があります。
ちなみに Stability Matrix で環境を構築し、 Stable Diffusion WebUI Forge で EasyNegative や negative_hand などを導入済みであれば、これらは Comfy UI でも共有してくれますので、これらの導入方法についても割愛させていただきます。
VAE を適用
Stable Diffusion WebUI Forge で生成した画像と比較して明らかなのが彩度とコントラストの不足。これは VAE が焼き込まれていないモデルに、別途 VAE を適用しなかったときにできる絵の典型。
そこでまず VAE を適用します。
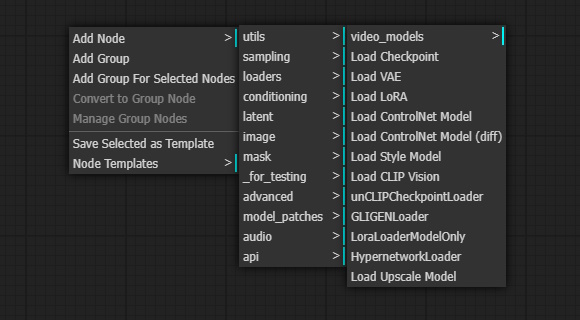
Comfy UI で新たに工程を追加する際は、基本、ノードを追加します。ノードも何もないところで右クリックすると出現する左図のようなメニューから、VAE を適用したい場合は「Add Nodes」―「Loader」と辿って「Load VAE」をクリックします。
すると、VAE を選択するカラムと、出力が「VAE」だけのノードが追加されます。VAE のファイルは Stable Diffusion WebUI Forge で環境が構築済みであれば共有されて、選択できるはずです。問題はここからです。
Comfy UI はノードを追加するだけではなく、ノード同士を接続してあげないと、そのノードの機能を果たしません。
この「Load VAE」のノードは比較的単純で、唯一の出力「VAE」を繋げてあげればいいだけです。では、どこに繋げるかというと、初期のワークフローで一番右端にある「Save Image」ノードの一つ前にある「VAE Decoder」ノードの入力「vae」に繋げてあげれば OK。初期の状態では、一番左端にある「Load Checkpoint」ノードの出力「VAE」と繋がっていますが、「Load VAE」の出力と繋げてあげると、これは切れるはずです。
言葉で説明してもわかりにくいので、説明用の Comfy UI の初期画面を下に用意しました。
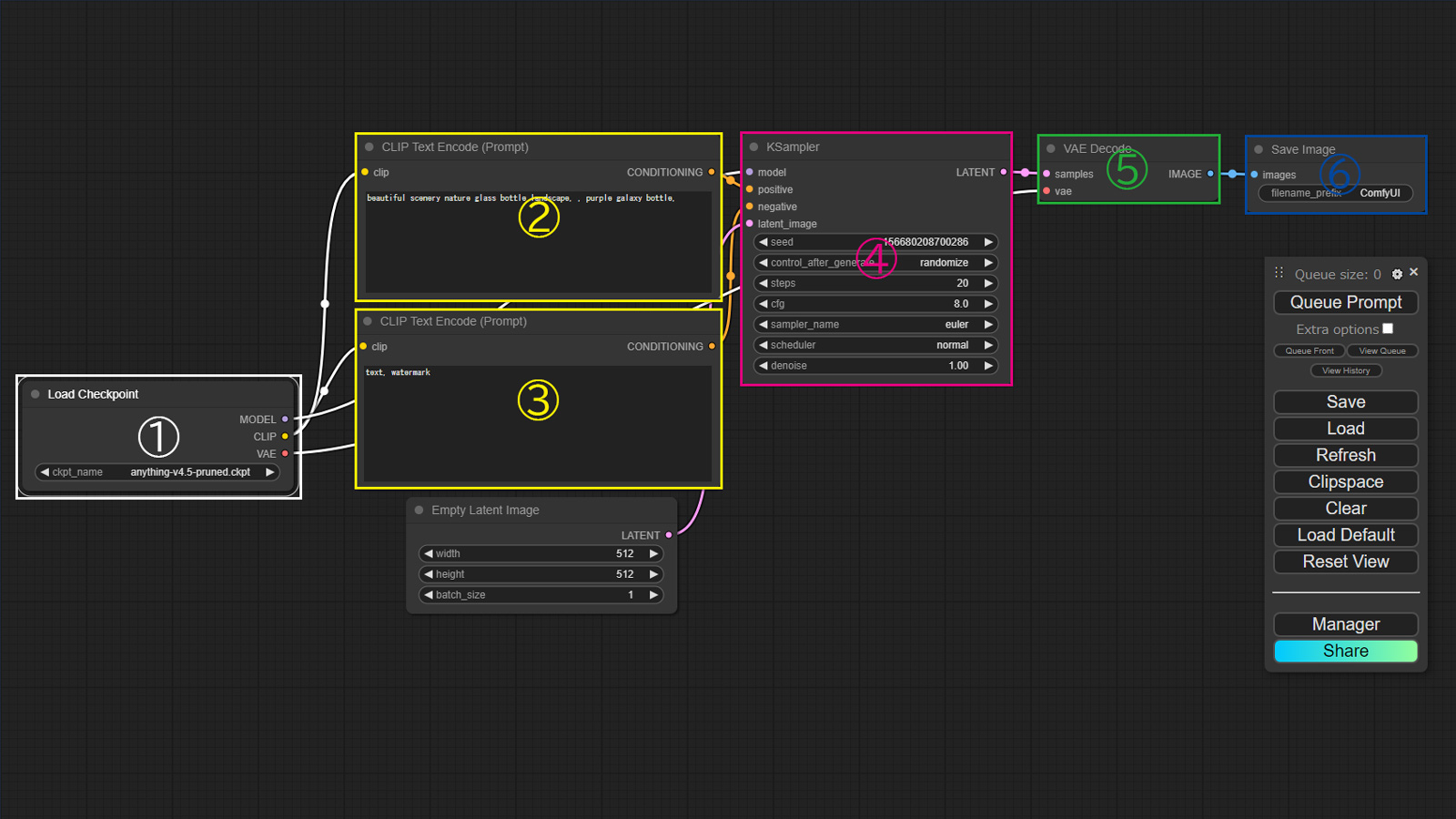
この図で説明すると、新しく加えた「Load VAE」ノードの出力 VAE は、⑤「VAE Decoder」ノードの入力「vae」に繋げます。すでに①「Load Checkpoint」ノードの出力「VAE」との接続は切断します。
プロンプトを修正し、VAE の適用まですると一気にここまで変わります。

LoRA の適用
次に、LoRA の適用。個人的にあまり LoRA は多用しませんが、 Detail Tweaker LoRA だけは画像のディテールアップのために、デフォルトで利かせています。
VAE と同様、メニューで「Add Nodes」―「Lodaer」と辿っていくとある「Load LoRA」をクリックして「Load LoRA」ノードと追加します
このノードは①「Load Checkpoint」ノードと②「Clip Text Encode(Prompt)」ノード、③「Clip Text Encode(Prompt)」ノード(ネガティブプロンプト)、および④「KSampler」ノードの間に配置します。
まずは①「Load Checkpoint」ノードの出力「MODEL」と④「KSampler」ノードの入力「model」の接続を切断し、代わりに①「Load Checkpoint」ノードの出力「MODEL」を「Load LoRA」ノードの入力「model」に、出力「MODEL」を④「KSampler」ノードの入力「model」に接続します
続いて、①「Load Checkpoint」ノードの出力「CLIP」と②および③「Clip Text Encode(Prompt)」ノードの入力「clip」を切断し、代わりに①「Load Checkpoint」ノードの出力「CLIP」を「Load LoRA」ノードの入力「clip」に、出力「CLIP」と②および③「Clip Text Encode(Prompt)」ノードの入力「clip」にそれぞれ接続します。
複数の LoRA を適用する際は、適用する LoRA の数だけ 「Load LoRA」ノードを直列に繋げて並べて、最後に適用する「Load LoRA」ノードの出力を、②および③「Clip Text Encode(Prompt)」ノード、⑤「KSampler」ノードにそれぞれ入力してあげれば OK です。
そして、LoRA(Detail Tweaker LoRA) を初期のパラメータは触らずに適用すると、さらにどん!一目見て分かるこのディテールアップ!まったく別絵です w ただ肌や素材の質感、特に髪の毛の描写を見ると、リアル系に振りたい場合、やはり Detail Tweaker LoRA の適用は Comfy UI でも欠かせません。

FaceDetailer の適用
最後に、Stable Diffusion WebUI Forge でも使っている、顔や手をいい感じで修正してくれる拡張機能 ADetailer 、Comfy UI でその代わりとなる「FaceDetailer」ノードを追加します。これは冒頭導入した ComfyUI Impact Pack に含まれています。
「Add Nodes」―「ImpactPack」―「Simple」と辿っていくとある「Face Detailer」をクリックして、「Face Detailer」ノードを追加します。見ただけでくじけそうな w これまでで最大のサイズのノードが追加されます。
出力は複数ありますが必須は「image」だけで、これは⑥「Save Image」ノードの入力「images」に接続します。
問題は入力です。
たくさんあるので表にまとめました。
| 「Face Detailer」ノードの入力 | 入力元 |
|---|---|
| image | ⑤「VAE Decoder」ノードの出力「IMAGE」 |
| model | ①「Load Checkpoint」ノードの出力「MODEL」 (LoRA を適用している場合は「Load LoRA」ノードの出力) |
| vae | ①「Load Checkpoint」ノードの出力「VAE」 (VAE を適用している場合は「Load VAE」ノードの出力) |
| positive | ②「Clip Text Encode(Prompt)」ノードの出力「CONDITIONING」 |
| negative | ③「Clip Text Encode(Prompt)」ノード(ネガティブ・プロンプト)の出力「CONDITIONING」 |
| bbox_detector | 新規で追加する「UltralyticsDetectorProvider」ノードの出力「BBOX_DETECTOR」 ※ model は初期設定 (bbox/face_yolov8m.pt) のまま |
| sam_model_opt | 新規で追加する「SAMLoader(Impact)」ノードの出力「SAM_MODEL」 |
| segm_detector_opt | bbox_detector への入力となるノードとは別に、新規で追加する「UltralyticsDetectorProvider」ノードの出力「SEGM_DETECTOR」 ※ model は segm/person_yolov8m-seg.pt に変更 |
このうち入力「image」、「model」、「clip」、「vae」、「positive」、「negative」は、これまで他のノードを追加した経験からなんとなく分かると思いますが、問題は「bbox_detector」と「sam_model_opt」。
これらの入力として「Add Nodes」―「ImpactPack」と辿って追加する「UltralyticsDetectorProvider」ノードが、新たに 2 つ必要です。
※ 【 2024/12/12 追記】最新の ComfyUI Impact Pack で「UltralyticsDetectorProvider」ノードは分割され、ComfyUI Impact Subpack に含まれるようになりました。事前に ComfyUI Impact Subpack もインストールして下さい。
「UltralyticsDetectorProvider」ノードは追加すると、初期設定のモデルが bbox/face_yolov8m.pt となっており、この状態だと出力「SEGM_DETECTOR」には「×」のアイコンが付くので、おそらく出力がされません。
この「×」はモデルを segm/person_yolov8m-seg.pt を変更すると消えるので、もう一つ追加する「UltralyticsDetectorProvider」ノードにはこれを指定して、出力「SEGM_DETECTOR」を「FaceDetailer」ノードの入力「segm_detector_opt」に使用します。
さらに「Add Nodes」―「ImpactPack」と辿って「SAMLoader(Impact)」ノードを足してこの出力を「FaceDetailer」ノードの入力「sam_model_opt」に接続します。
「FaceDetailer」ノードを追加して、接続さえしてしまえば、多々パラメータはありますが初期設定のままで OK。
実際に適用してみると、これまでのものと違って違いは分かりにくいですが、Face Detailer 適用前は、瞳もヘテロクロミア気味ですし、ナチュラルメイクな感じですが、適用後は左右で瞳の色も同じで、唇も艶やかになり、フルメイクした感じに、顔だけが見事に修正されているのがおわかりいただけますでしょうか?

CLIP Set Last Layer
Stable Diffusion WebUI Forge では、モデルによっては Clip Skip を 2 に設定することを推奨するものがあり、当方でもデフォルトで 2 で運用しておりますが、この Clip Skip を Comfy UI ではどうやって設定するかというと、これもノードを追加します。
「Add Nodes」―「conditioning」と辿って「CLIP Set Last Layer」ノードを追加。追加した段階で、パラメータである stop_at_clip_layer は「-1」となっていますので、これを「-2」とすると、Stable Diffusion WebUI Forge で Clip Skip を 2 に設定することと同義になります。(意味は詳しく分かってません w)
このノードを①「Load Checkpoint」ノードの直後、②「Clip Text Encode(Prompt)」ノード、③「Clip Text Encode(Prompt)」ノード(ネガティブプロンプト)の間に( LoRA を適用する場合はその前に)挿入します。
上記のサンプルでは全て最初にこの「CLIP Set Last Layer」ノードを追加して出力しています。
ここまでしてできあがった今回のワークフローがこちら。
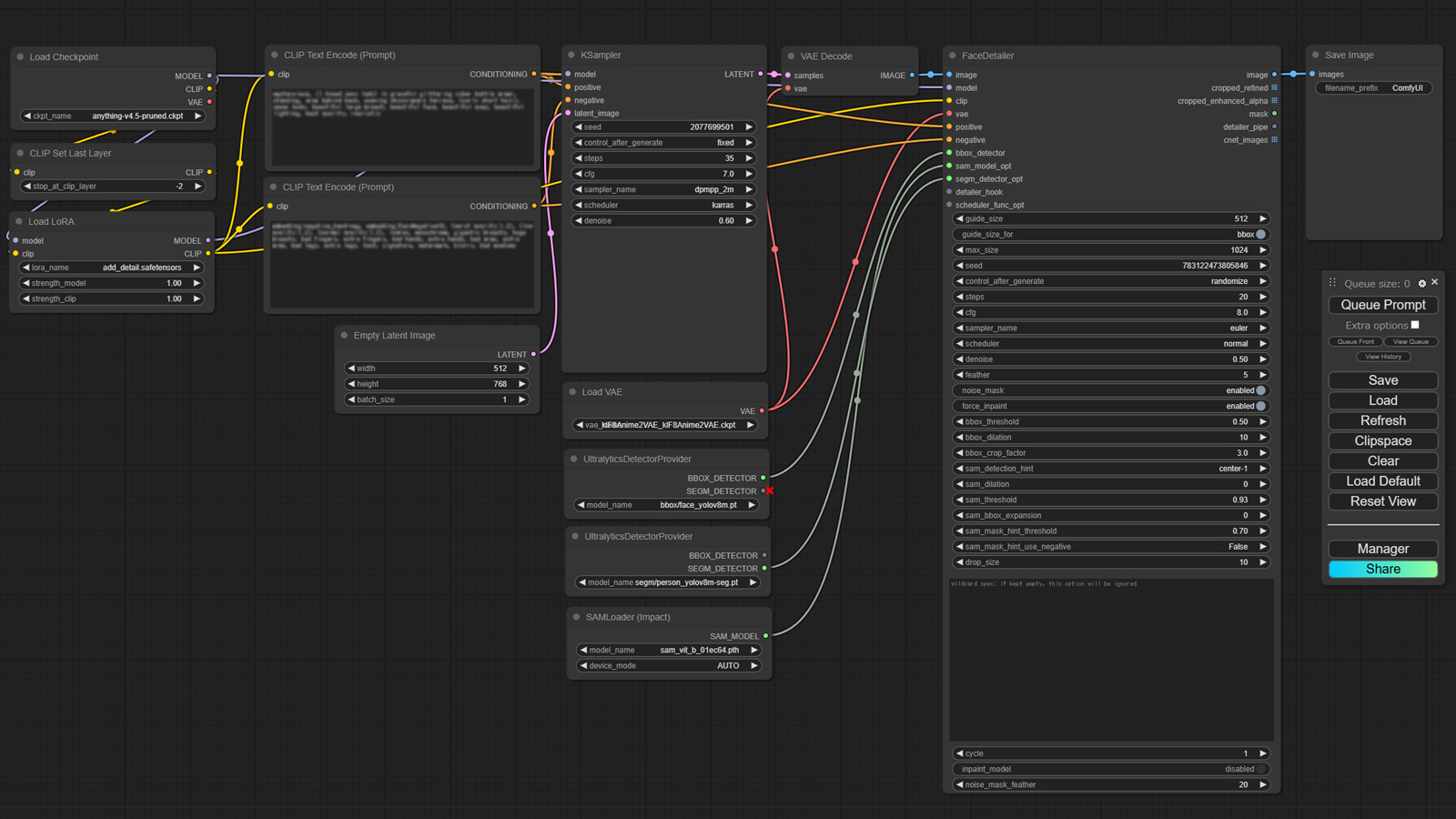
最初にこれ見たら「うげっ!」ってなりますよね w 自分で作ったならまだしも、人様が作ったものをならなおさらです。まぁわかりにくい w
しかし、この記事を読みながら進めればできるはずです。私も 3 回くらい試しました ww
一気にアップスケールまでまとめるつもりだったのですが、あまりにも長大になってしまったので、今回はここまで。
次回は「アップスケール編」で上記のワークフローをさらに拡張していきます。