




SD1.5 モデルでこのレベルの絵が作れるようになった Comfy UI のワークフローで、いよいよ SDXL モデルでの画像生成にチャレンジします。
SDXL で生成する画像サイズ
よく知られているように Stable Diffusion では、モデルデータを学習する際に用いられた画像サイズに基づいたサイズの画像を生成しないと、見るに耐えない絵が出てきたりします。
SD1.5 モデルを使う場合は、512×512 の画像データで学習されているため、当方でも 512×768 サイズ(縦横逆転でもかまいませんが、縦長の方がいい絵が出る確率が高く感じます)で試行しています。
これが SDXL モデルの場合、1024×1024 の画像データ学習されているために、以下のような画像サイズが推奨されています。
- 1024×1024
- 896×1152
- 832×1216
- 768×1344
- 672×1568
- 576×1728
※ 縦横逆転でも可
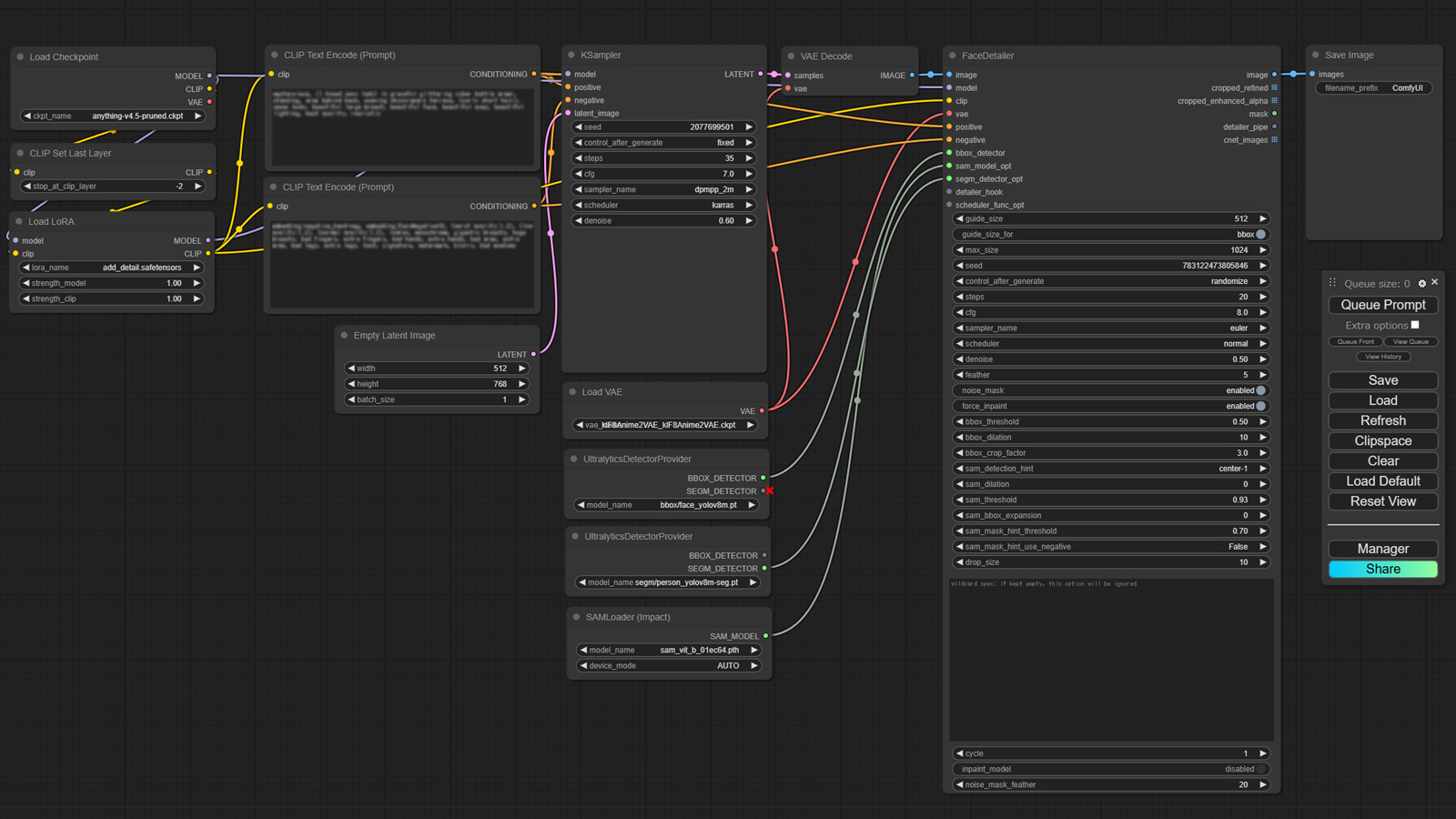
なぜこんな数字になるのかは、いまいち理解できてないのですが、先に結果論になりますが、モデルを変えつつ、試行を繰り返した結果、ポートレイトでもランドスケープでも 896×1152 と言うサイズが、一番当たる確率が高かったように思えましたので、これを採用しました。また 896×1152 と言うサイズなので、ひとまず 「UltimateSDUpscale」によるアップスケールまで行わない、画質向上編で完成させた以下のワークフローを使用して、「Empty Latent Image」ノードの幅 width を 896 、高さ Hight を 1152 と修正して試行を行いました。
Detail Tweaker XL
Refiner は使いませんので、フローそのものは修正しません。
しかし、SD1.5 の時に使っていた Detail Tweaker LoRA は SDXL では使えませんので、これは Detail Tweaker XL という別の LoRA を使います。
それで何度か、試行してみたこれも結果論なんですが、これまでは Stable Diffusion WebUI Forge などの設定を参考にしていた「KSampler」ノードや「FaceDetailer」ノードの step と cfg ですが、step は最低でも 50 、cfg は 7.0 より 8.0 の方が良好な結果が得られるように思いましたので、ここは変更しました。
最後に VAE は、モデルのものを使わず、SharpSpectrumVAEXL 一本にしています。
いざ、SDXL !
いよいよ SDXL やってみた!
Fooocus をイジイジしていたときに使っていたモデルでは、ろくな絵ができなかったので、SDXL で今、評判の良さそうなモデルを新たにダウンロード。
- AlbedoBASE XL v2.1
- CyberRealistic XL v2.2
- Juggernaut XL v9
いきなりリアル系のモデルでやってみた!



すばらしい!一見して、SD1.5 とはレベルが違う質感。特に金属部分などはすばらしく、また背景の書き込みも明らかにレベルが上。実はこれ、JPEG 変換したときに若干、品質が落ちているのですが、正直、それでも Fooocus で何度か出してみたものと比べて、できがいいように思います。
…が。
これは Fooocus を使っていたときも思ったのですが、「cyber battle armor」というプロンプトで表現しているこの衣装に感じるそこはかとない B 級映画テイスト… (_ _;A
その他、なんとなくですがプロンプトの言うことを聞いてないようなこのポーズ。
プロンプト修行が足らんのか?とも思ったのですが、SD1.5 でお絵かきするときは、アニメ系のモデルで生成した画像を、リアル系のモデルに置き換えるということをしていて、この時使っているモデル AnythingElse の XL 版もあったので、試しに以下のモデルで生成してみました。
- Anything XL
- Animagine XL v3.1


やっぱり…アニメ系の方が断然いい w A 級のアニメ映画クラス。ポーズもプロンプトの言うことを聞いてくれている気がする。ちなみにどれも SEED 値やプロンプトは固定して、モデルだけを変えています。
特に Animagine XL は素晴らしい!こういう絵をもっとリアル系に近づけていきたい!と言うわけで、今回からアイキャッチも、アニメ系のモデルで何枚か生成したもの中でいけてるものに変えてみました。
やはり SDXL でも、アニメ系のモデルで生成した画像を、リアル系に置き換えた方がいいのか…と言うわけで、今、Comfy UI での img2img を研究中です。