




Comfy UI のインストールから、初期のワークフローに、VAE や LoRA 、 FaceDetailer を適用して、ついにここまでクオリティがアップしてきました。
ここまで 512×768 のサイズで試行を続けて、満足できるクオリティになったので、いよいよこれをフル HD サイズにアップスケールして、仕上げます。
これには、準備編で先にインストールしていた拡張ノード「UltimateSDUpscale」を使います。
UltimateSDUpscale の追加
例の如く、右クリックすると出現するメニューから「Add Nodes」―「image」―「upscaling」と辿って「Ultimate SD Upscale」をクリックしてノードを追加します。
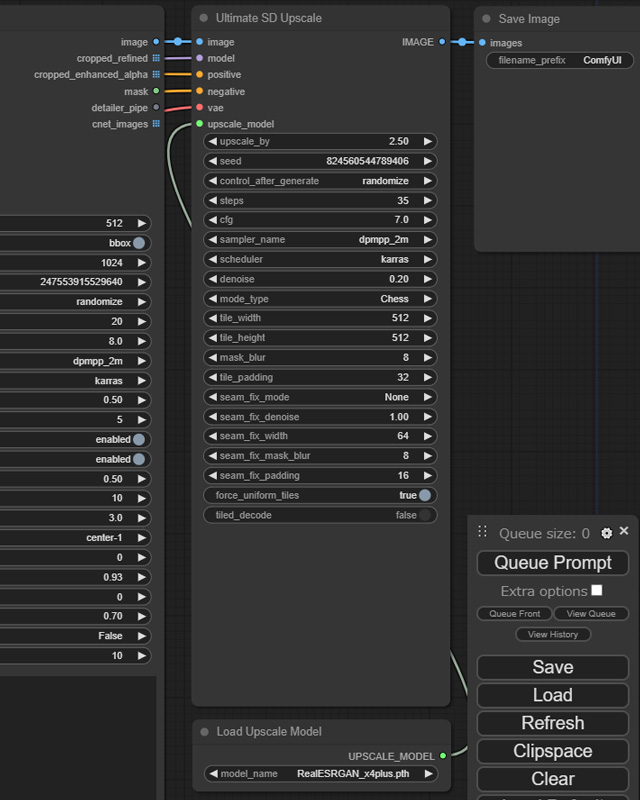
右のようなそこそこ大きいノードですが、出力は一つ「IMAGE」だけで、入力は 6 つもありますが、「image」「model」「positive」「negative」「vae」とここまで見たことのあるものが多く、見当が付かないのは「upscale_model」だけでしょう。
まずこのノードは、最終出力となる「Save Image」ノードの直前に配置します。
各入力の接続先を表にまとめると以下のようになります。
| 「Ultimate SD Upscale」 ノードの入力 | 入力元 |
|---|---|
| image | 「Save Image」ノードの入力「images」に接続していた出力 |
| model | 「Load Checkpoint」ノードの出力「MODEL」 (LoRA を適用している場合は「Load LoRA」ノードの出力) |
| positive | 「Clip Text Encode(Prompt)」ノードの出力「CONDITIONING」 |
| negative | 「Clip Text Encode(Prompt)」ノード(ネガティブ・プロンプト)の出力「CONDITIONING」 |
| vae | 「Load Checkpoint」ノードの出力「VAE」 (VAE を適用している場合は「Load VAE」ノードの出力) |
| upscale_model | 新規で追加する「Load Upscale Model」ノードの出力「UPSCALE_MODEL」 |
問題の upscale_model の入力は、「Add Nodes」―「loaders」と辿って「Load Upscale Model」をクリックして追加したノードの出力「UPSCALE_MOEDL」となります。
この「Load Upscale Model」ノードは、パラメータとしてモデルを指定しますが、選択肢は 2 つで、リアル系の画像をアップスケールする際は「RealESRGAN_x4plus.pth」を、二次元系の場合は「RealESRGAN_x4plus_anime_6B.pth」を指定します。
肝心の「Ultimate SD Upscale」ノードにも、パラメータはわんさとありますが、弄ったところは mode_type を「chess」にして、Stable Diffusion WebUI Forge でも使用している Ultimate SD Upscale にはない sampler_name と scheduler 、さらに step と cfg も「KSampler」ノードに合わせました。
あとは「Face Detailer」ノードから出力されてくるのが 512×768 のサイズの画像なので、これを 1080×1920 のフル HD まで大きくするために upscale_by を 2.5 に設定しています。
この「Ultimate SD Upscale」を追加して、いよいよできあがったワークフローがこちら!

長大です。よくここまでやったと自分を褒めてあげたいです w
これでいよいよ。アップスケールまでかました絵がこちら!


ほぼ同じプロンプトを使用していますが、Stable Diffusion WebUI Forge と Comfy UI で同じ絵が生成できないことは周知の事実(準備編 参照)。同じモデルを使用して、絵のタッチというかトーンに差は感じますが、ことクオリティに関しては追いついたのではないでしょうか?
ちなみに同じワークフローでモデルを変えて生成してみたのがこちら。


そして普段、あまりやらないのですが、試しに直接リアル系のモデルで生成してみると…



これは SDXL でも…と密かに期待を抱きつつ…次はいよいよこのワークフローを持って SDXL モデルでの生成に挑む!(予定)